
On 1st December 2020, Royal Botanic Garden Edinburgh led the second of three workshops to take place as part of the Towards a National Collection Foundation Project Engaging Crowds: citizen research and heritage data at scale. This project is investigating the current and future landscape of cultural heritage crowdsourcing. It is gathering insights into best practice and experimenting with novel methods of volunteer engagement via three new citizen research projects.
In this online workshop we explored the crowdsourced data cycle in cultural heritage with an emphasis on what happens to the data after a citizen research project comes to an end.
In the first half we heard presentations from four different citizen research projects on our workshop data themes: reingestion, reusability, rediscovery and research.
Data Re-use
Mutual Muses, Melissa Gill & Nathaniel Deines – J. Paul Getty Trust

The Mutual Muses project sought to transcribe the correspondence between Lawrence Alloway and Sylvia Sleigh, key figures of the 20th century art world. The focus was to create quick access to open data (Creative Commons license CC0) for two main audiences – the volunteer transcribers and digital humanities scholars. Through consultation with these user groups an interim solution was developed in the form of a GitHub repository. This platform allowed the project data to be shared as both a chronologically readable book and a research-friendly dataset. The project’s long-term goal is to host the data on their online research collections viewer.
Data Quality
Anti-Slavery Manuscripts, Tom Blake – Boston Public Library & Dr Samantha Blickhan – Zooniverse
The Anti-Slavery Manuscripts project (ASM) was one of two bespoke text transcription projects that formed part of the Zooniverse-led “Transforming Libraries and Archives Through Crowdsourcing” project, funded by a National Leadership Grant from the US Institute for Museum and Library Services . The research aims of this project included exploring whether the then-current Zooniverse methodology of multiple independent transcribers produced better results than allowing volunteers to collaborate. As part of the ASM project, the team ran an A/B experiment looking at the quality of individual versus collaborative transcription.
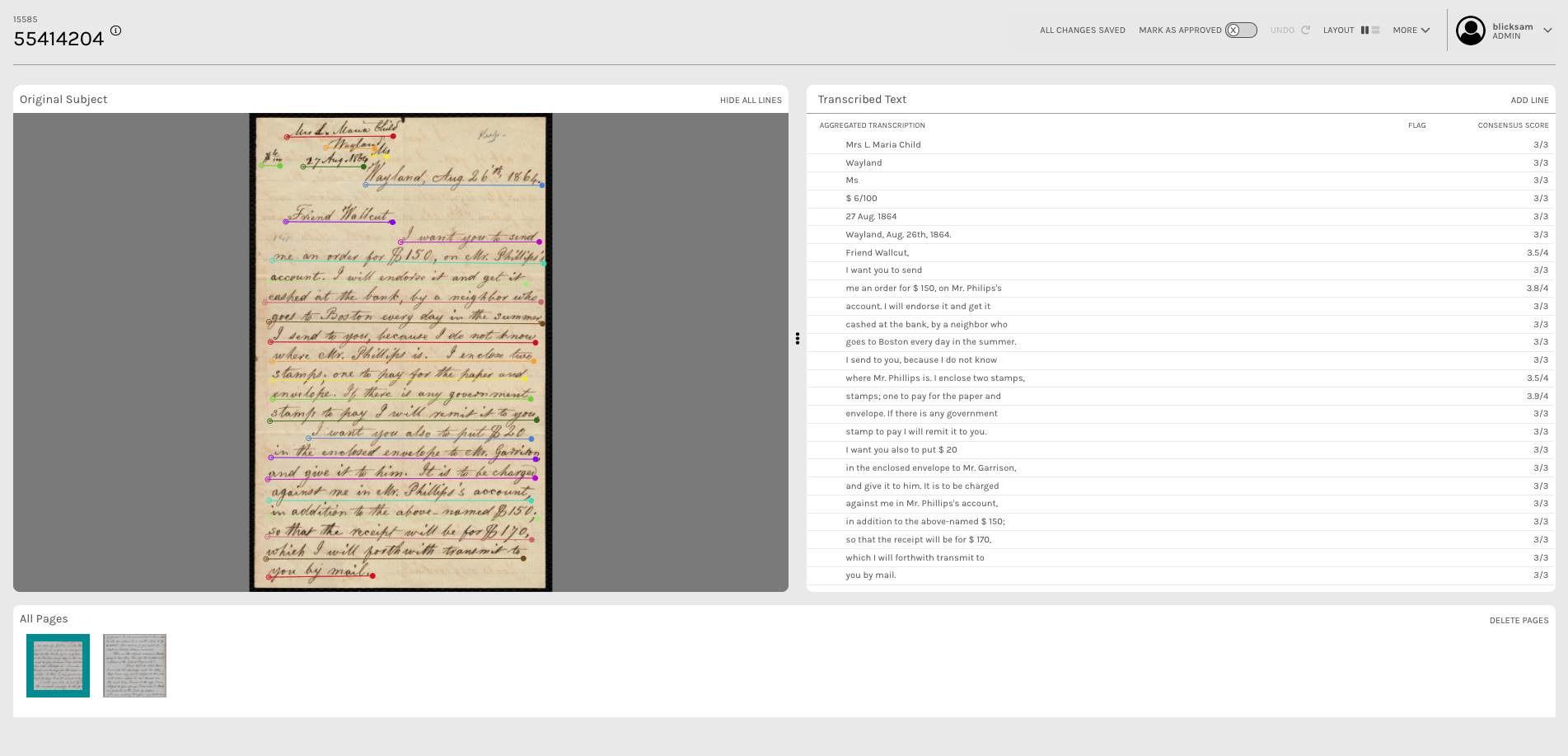
The experiment found that volunteers who were able to see and interact with other people’s transcriptions produced significantly higher-quality data with a quicker turnaround time (Blickhan et al. 2019). The results from the Anti-Slavery Manuscripts project are currently being reviewed by the Boston Public Library team using the newly-developed Aggregate Line Inspector and Collaborative Editor (ALICE) tool, developed by Zooniverse with funding from the US National Endowment for the Humanities (https://www.neh.gov/). ALICE is in the final rounds of beta testing and will launch publicly in 2021 as a free-to-use tool for researchers building text transcription projects on the Zooniverse platform. The tool will allow people to work collaboratively to view, annotate and edit the output of text transcription projects. To get a taste of what’s to come you can find some video tutorials of the tool here: https://www.vimeo.com/zooniverse
Data ingestion and research
Notes from Nature, Mike Denslow – University of Florida
Notes from Nature hosted on the Zooniverse platform is a community-focused project that seeks to engage the public in transcribing collection labels of natural history specimens. So far, the project has captured over 3.5 million transcriptions from the estimated 10 billion specimens housed in Natural History collections across the globe.
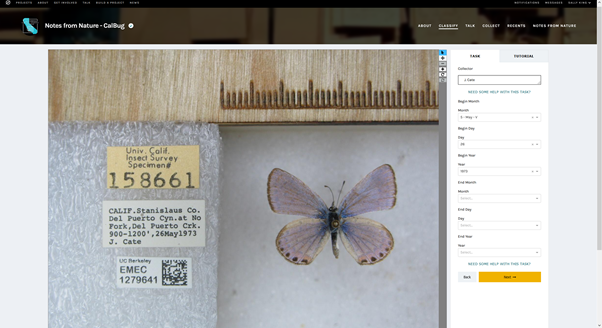
This project has an established ingestion protocol which allows transcription data to be added to pre-existing stub records in the South East Regional Network of Expertise and Collections (SERNEC) data portal (one of 18 portals within the Symbiota family that house over 18 million biodiversity records). This is no mean feat as many institutions struggle to incorporate transcription into their in-house collections management systems. It is great to see such a strong relationship between a large content discovery platform and a public engagement project. Such a relationship enables accessible, traceable data that is research-ready.
Data-driven research
Micropasts, Daniel Pett – Fitzwilliam Museum & Dr Chiara Bonacchi – University of Stirling
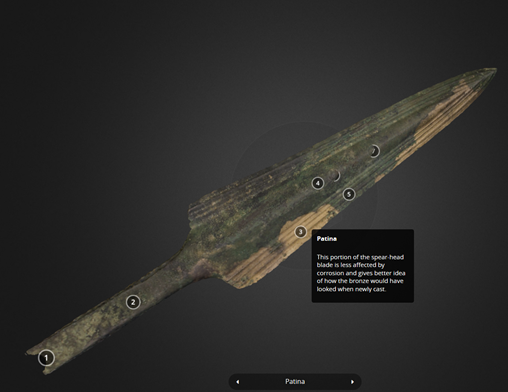
Micropasts is centred around three open pillars: open data, open software and open coding. Regardless of the stage and progress of the project the ethos is to make the data instantly available. It takes participation to the next level, creating a collaborative space between academics and other communities in archaeology.
The result is co-produced open data sets of a variety of media. These can then be used in co-designed follow-up research by the same groups using open source software, Pybossa, and additional reproducible, shareable code.
Deconstructing ideas about data
With food for thought from our presenters, participants then split into break-out rooms to discuss questions around maximizing data accessibility, re-use and ingestion into collections management systems. Each sub-group shared a summary of their discussion with the wider group in the final session of the workshop.
I think the most profound thing that came out of this for me was a question linked to an unspoken paradigm:
Are crowdsourced datasets any different to any other kind of data?
The current default position of many institutions is to treat crowdsourced data differently from data created by in-house staff or humanities scholars. This often involves subjecting it to more rigorous quality checks for example. However, if the source of all datasets is clearly indicated on discovery platforms then they can be treated equally. Correct attribution of data serves two purposes: it respects the contributions of volunteers, making sure they are credited for the data they produce. It’s second purpose is to ensure that researchers have a clear understanding of the data they choose to work with, and take any resulting idiosyncrasies into account.
With that paradigm shift the rest falls into place in terms of project planning and possibilities:
What data standards are required?
This should inform volunteer training and ongoing support for citizen researchers. Any support needs to be created in such a way that it allows volunteers to confidently and accurately document, tag, transcribe the treasures of our collections. It’s also important to be frank with ourselves and recognize that data created internally within an institution doesn’t necessarily provide a consistent baseline. What should we expect of volunteers if the data we already hold in our institutions are not completely standardised and error free?
Are you looking to create new data or enhance existing data?
One of the largest problems that provides support for the idea that crowdsourced data are different is the misalignment that frequently occurs between in-house databases and the data that come out of citizen research platforms. It can often feel like trying to put a square peg into a round hole! Tackling this misalignment should be framed within the need to make the data outputs quickly and easily accessible and attributed to creators. Raw data can be made available – it doesn’t necessarily have to be ‘polished’ and in our internal collections management system before it becomes widely accessible. Data should, however, be in a format that is searchable and easy to find.
Could we move to a more co-creative approach and create a project application that aligns better with our in-house systems?
For some this approach is feasible but comes with the caveat of at least a basic knowledge of coding and version control of said code. I think the most beneficial way to address this is to work more closely with pre-existing crowdsourcing platforms and their volunteer base to communicate and advocate for our needs as users of these platforms. This would benefit all parties as better data outcomes guarantee a longer and more fruitful relationship and better research outcomes.
Next steps
We would like to say a massive thank you to everyone who presented at or took part in the discussion at our workshop. It was hugely exciting to hear from such a range of crowdsourcing practitioners. We are working on a report summarising the workshop, which will be made available on the Engaging Crowds website. We will be running a final project workshop to gather views of volunteer transcribers later in 2021 – more details coming soon.
With thanks to the Engaging Crowds project partners:
- The National Archives
- Royal Botanic Garden Edinburgh
- Royal Museums Greenwich
- Zooniverse, University of Oxford

References and Resources
Child, Lydia Maria, and Robert Folger Wallcut. “Letter from Lydia Maria Child, Wyland, to Robert Folger Wallcut, Aug. 26 ‘th, 1864.” Correspondence. August 26, 1864. Digital Commonwealth, https://ark.digitalcommonwealth.org/ark:/50959/wm118b234. Accessed March 09, 2021.
Samantha Blickhan, Coleman Krawczyk, Daniel Hanson, Amy Boyer, Andrea Simenstad, et al. “Individual vs. Collaborative Methods of Crowdsourced Transcription.” Journal of Data Mining and Digital Humanities, 2019, https://hal.archives-ouvertes.fr/hal-02280013v2. Accessed 16 March 2021.
https://crowdsourced.micropasts.org/
https://sketchfab.com/micropasts